Fusion Patterns#
The following fusion patterns represent subgraphs that the oneDNN Graph API identifies as candidates for partitions. You can define computation graphs according to these patterns, get partitions from the graph, compile the partitions into compiled partitions, and execute them to obtain results. See Graph API Basic Concepts for more details about the programming model.
Note
The following categories will be used in describing a fusion pattern:
Pattern |
Description |
|---|---|
Scaled Dot-Product Attention |
This pattern is widely used for attention mechanisms in transformer models, e.g., BERT and GPT. Refer to Scaled Dot-Product Attention (SDPA) for more details. |
Grouped Query Attention |
This pattern is widely in LLM models like llama2 70b and llama3 to reduce the memory usage of the kv cache during inference. Refer to Grouped Query Attention (GQA) for more details. |
Scaled Dot-Product Attention with Compressed Key/Value |
This pattern is used for memory-efficient attention mechanisms. Refer to Scaled Dot-Product Attention with Compressed Key/Value for more details. |
Gated Multi-Layer Perceptron (Gated-MLP) |
This pattern is widely used for enhancing feedforward layers in transformer models, e.g., Vision Transformers (ViT). Refer to Gated Multi-Layer Perceptron (Gated-MLP) for more details. |
MatMul Fusion Patterns |
This pattern is widely used in language models and recommendation models, for example BERT, DLRM, etc. Refer to MatMul Fusion Patterns for more details. |
Quantized MatMul Fusion Patterns |
This pattern is widely used for efficient matrix multiplication in quantized models. Refer to Quantized MatMul Fusion Patterns for more details. |
Convolution Fusion Patterns |
This pattern is widely used in Convolution Neural Networks, e.g., ResNet, ResNext, SSD, etc. Refer to Convolution Fusion Patterns for more details. |
Quantized Convolution Fusion Patterns |
This pattern is widely used in quantized Convolution Neural Networks. Refer to Quantized Convolution Fusion Patterns for more details. |
ConvTranspose Fusion Patterns |
This pattern is widely used for upsampling in Generative Adversarial Networks. Refer to ConvTranspose Fusion Patterns for more details. |
Quantized ConvTranspose Fusion Patterns |
This pattern is widely used in quantized Generative Adversarial Networks. Refer to Quantized ConvTranspose Fusion Patterns for more details. |
Binary Fusion Patterns |
Fusion Patterns related to binary operations (refer to above Note for more details). This pattern is widely used in language models and recommendation models, e.g., BERT, DLRM. Refer to Binary Fusion Patterns for more details. |
Unary Fusion Patterns |
Fusion Patterns related to unary operations (refer to above Note for more details). This pattern is widely used in Convolution Neural Networks. Refer to Unary Fusion Patterns for more details. |
Interpolate Fusion Patterns |
This pattern is widely used for image processing. Refer to Interpolate Fusion Patterns for more details. |
Reduction Fusion Patterns |
Fusion Patterns related to reduction operations like ReduceL1, ReduceL2, ReduceMax, ReduceMean, ReduceMin, ReduceProd, ReduceSum. This pattern is widely used for data processing, for example loss reduction. Refer to Reduction Fusion Patterns for more details. |
Pool Fusion Patterns |
Fusion Patterns related to pool operations like MaxPool, AvgPool. This pattern is widely used in Convolution Neural Networks. Refer to Pool Fusion Patterns for more details. |
Norm Fusion Patterns |
Fusion Patterns related to norm operations like GroupNorm, LayerNorm, BatchNormInference. This pattern is widely used in Convolution Neural Networks, for example DenseNet. Refer to Norm Fusion Patterns for more details. |
SoftMax Fusion Patterns |
This pattern is widely used in Convolution Neural Networks. Refer to SoftMax Fusion Patterns for more details. |
Other Fusion Patterns |
Refer to the below section for more details. |
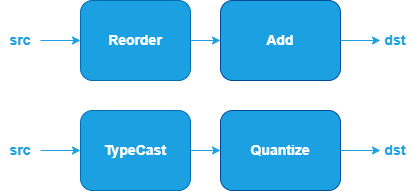
Other Fusion Patterns#
The Other category currently includes operations such as: Reorder, TypeCast, and Quantize.
oneDNN supports specialized fusion patterns for Other operations to optimize performance and reduce memory bandwidth requirements.
Pattern Structure: