
Grouped Query Attention (GQA)#
Overview#
In a typical Scaled Dot-Product Attention (SDPA) [1], the input Query, Key, and Value tensors have the same head number. It becomes a performance bottleneck to load the Key and Value tensors in each generation step, especially when the sentence length gets longer.
To reduce the memory bandwidth overhead of loading the Key and Value tensors, Multi-Query Attention (MQA) [2] is created by reducing the head number of Key and Value tensors to one which means multiple Queries will map to the same single Key and Value tensor. However, MQA may lead to model quality degradation and training instability. Therefore, Grouped-Query Attention (GQA) [3], an interpolation between the typical SDPA and MQA, is proposed with single Key and Value head per a subgroup of Query heads. The head number of Key and Value equals to the group number of Query heads.
The notations used in the document:
N: the mini-batch size.
H_q: the head number of Query.
H_kv: the head number of Key or Value.
N_rep: H_q / H_kv, indicates how many Query heads are mapped to one Key head.
S: the sequence length.
D: the size of each head.
GQA Pattern#
Similar to how SDPA is supported, the GQA pattern is also defined as a directional acyclic graph (DAG) using oneDNN Graph API.
GQA for Inference#
oneDNN extends the SDPA pattern to support two types of floating-point (f32, bf16, and f16) GQA patterns. The blue nodes are required when defining a GQA pattern while the brown nodes are optional. The key difference between the two types of GQA patterns lies in whether the input and output tensors have 4D or 5D shapes. The optional StaticReshape operations are used to convert the tensors between 4D and 5D shape formats, depending on whether the input and output tensors are in 4D shapes.
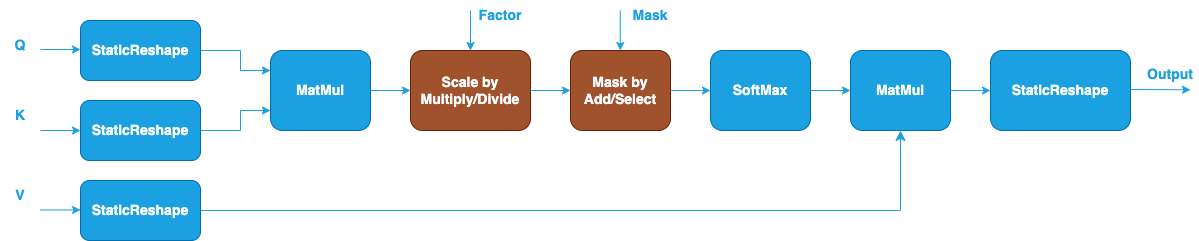
GQA Inference Pattern with 4D input and output#
Due to the broadcasting semantics of MatMul, implementing GQA often requires additional tensor manipulation. Specifically, when working with 4D input tensors, where Query has shape (N, H_q, S, D) and Key/Value has shape (N, H_kv, S, D), it is necessary to introduce extra StaticReshape operations to align tensor dimensions for the MatMul operations. Therefore, the 4D GQA pattern involves the following differences:
The input Query has shape (N, H_q, S, D). It will be reshaped to (N, H_kv, N_rep, S, D) by splitting H_q dimension into H_kv and N_rep. The reshaping can be constructed using the StaticReshape operation in Graph API.
Similarly, the input Key and Value have shape (N, H_kv, S, D). They will be reshaped to (N, H_kv, 1, S, D) to meet the input shape requirement of MatMul operation.
The second MatMul calculates the dot products between the probabilities after SoftMax and Value nodes and generates output with shape (N, H_kv, N_rep, S, D).
Another StaticReshape operation is applied to the output of the second MatMul to convert the shape into (N, H_q, S, D) by combining H_kv and N_rep dimensions.
The input scale factor and mask in the pattern also need to meet the operations’ shape requirement which can be achieved through StaticReshape similarly. Besides that, they have the same definition as described in the typical SDPA pattern.
GQA Inference Pattern with 5D input and output#
To simplify the process and avoid unnecessary reshaping, the native 5D GQA pattern supported by oneDNN can be used. In this approach, the input Query, Key, and Value tensors are provided in a grouped format.
The input Query has a 5D shape: (N, H_kv, N_rep, S, D)
The input Key/Value has a 5D shape: (N, H_kv, 1, S, D)
The second MatMul calculates the dot products between the probabilities after SoftMax and Value nodes and generates output with shape (N, H_kv, N_rep, S, D).
The input scale factor and mask in the pattern must meet the operations’ shape requirement.
GQA for Training Forward Propagation#
oneDNN defines floating-point (f32, bf16, or f16) GQA for training forward propagation as follows. The blue nodes are required while the brown nodes are optional.
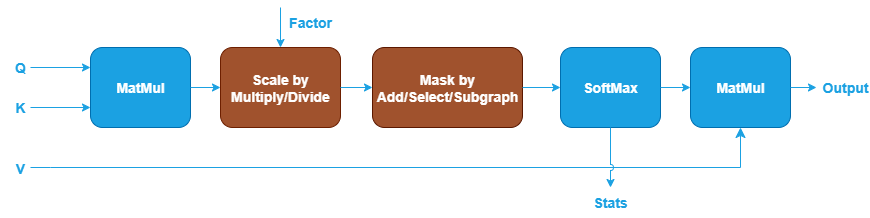
The training forward pattern only supports 5D input and output tensors. The key differences from the 5D inference pattern are:
GQA for Training Backpropagation#
oneDNN defines floating-point (f32, bf16, or f16) GQA for training backpropagation as follows, it currently supports 5D input and output tensors. The blue nodes are required while the brown nodes are optional.
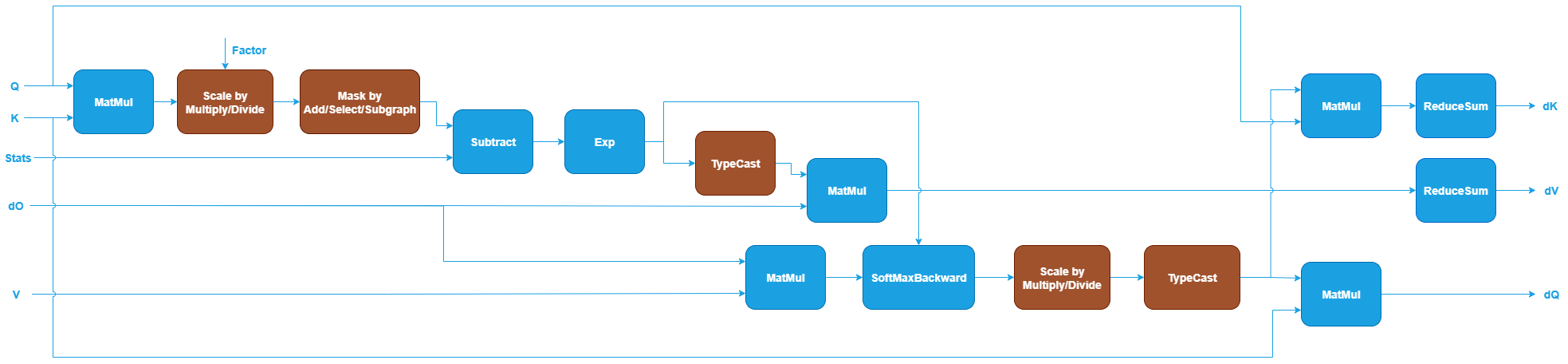
The first MatMul computes the score between Query and Key, similar to inference and training forward propagation. See MatMul in Graph API.
The Scale node is optional and scales the output of the first MatMul using a scaling factor. This can be implemented using Multiply or Divide in Graph API.
The Mask node is optional and applies an attention mask to the output of the previous Scale node. For training backpropagation, only explicit user-generated masks are currently supported. The mask definition is the same as in inference and training forward propagation.
The Subtract and Exp operations take the masked output and
Statsas inputs and recover the probabilities computed by SoftMax in the training forward propagation. See Subtract and Exp in Graph API.The Dropout, TypeCast, MatMul and ReduceSum operations after Exp are used to compute the gradients with respect to Value. TypeCast is required for
bf16andf16training scenarios. ReduceSum reduces the Value gradients from (N, H_kv, N_rep, S, D) to (N, H_kv, 1, S, D). See TypeCast and ReduceSum in Graph API.The MatMul takes the output gradients (
dO) and the Value as inputs to compute the gradients of the probabilities.The Dropout operation takes the gradients of the dropped probabilities as input and computes gradients with respect to the normalized probabilities. See Dropout in Graph API.
The Multiply, ReduceSum, Subtract, and Multiply operations are used to compute the gradients with respect to the scaled output according to the formula: dS = P * (dP - ReduceSum(O * dO)), where P denotes the normalized probabilities and dP denotes the gradients with respect to them.
The Scale node after Multiply corresponds to the forward Scale node and is used to compute the gradients of the score.
The TypeCast, two MatMul and ReduceSum operations after the Scale node compute the gradients with respect to Query and Key, respectively. TypeCast is required for
bf16andf16training scenarios. ReduceSum reduces the Key gradients from (N, H_kv, N_rep, S, D) to (N, H_kv, 1, S, D).The optional End operation marks the output of Multiply as a partition output, representing the gradients with respect to the Mask. Note that the output shape of
dMis (N, H_kv, N_rep, S, S) and the data type isf32. The library does not perform any reduction or typecast on this output (for example, reducing to (1, 1, 1, S, S), casting tof16).
Data Types#
oneDNN supports the floating-point GQA pattern with data types f32, bf16, and f16. You can specify the data type via the input and output data type fields of logical tensors for each operation. oneDNN does not support mixing different floating data types in a floating-point GQA pattern.
The definition of the data types and support status on different CPU and GPU platforms follow the general description in Data Types.
Implementation Limitations#
oneDNN primitive-based GQA is implemented as the reference implementation on both Intel Architecture Processors and Intel Graphics Products. The reference implementation requires memory to store the intermediate results of the dot products between Query and Key which takes \(O(S^2)\) memory. It may lead to Out-of-Memory error when computing long sequence length input on platforms with limited memory.
The GQA patterns functionally support all input shapes meeting the shape requirements of each operation in the graph.
CPU
Optimized implementation is available for 4D and 5D GQA patterns. For 4D, the shapes are defined as (N, H_q, S, D) for Query and (N, H_kv, S, D) for Key and Value. For 5D, the shapes are defined as (N, H_kv, N_rep, S, D) for Query and (N, H_kv, 1, S, D) for Key and Value.
Optimized implementation is available for OpenMP runtime and Threadpool runtime on Intel Architecture Processors.
Specifically for OpenMP runtime, the optimized implementation requires
N * H_q > 2 * thread numberto get enough parallelism.
GPU
Optimized implementation is available for 4D and 5D GQA patterns. For 4D, the shapes are defined as (N, H_q, S, D) for Query and (N, H_kv, S, D) for Key and Value. For 5D, the shapes are defined as (N, H_kv, N_rep, S, D) for Query and (N, H_kv, 1, S, D) for Key and Value.
Optimized implementation is available for floating-point GQA with
f16andbf16data type andD <= 512on Intel Graphics Products with Intel(R) Xe Matrix Extensions (Intel(R) XMX) support.
Example#
oneDNN provides a GQA inference example and a GQA training example demonstrating how to construct 5D floating-point GQA patterns for inference and training with oneDNN Graph API on CPU and GPU with different runtimes.
References#
[1] Attention is all you need, https://arxiv.org/abs/1706.03762v7
[2] Fast Transformer Decoding: One Write-Head is All You Need, https://arxiv.org/abs/1911.02150
[3] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, https://arxiv.org/abs/2305.13245