Introduction
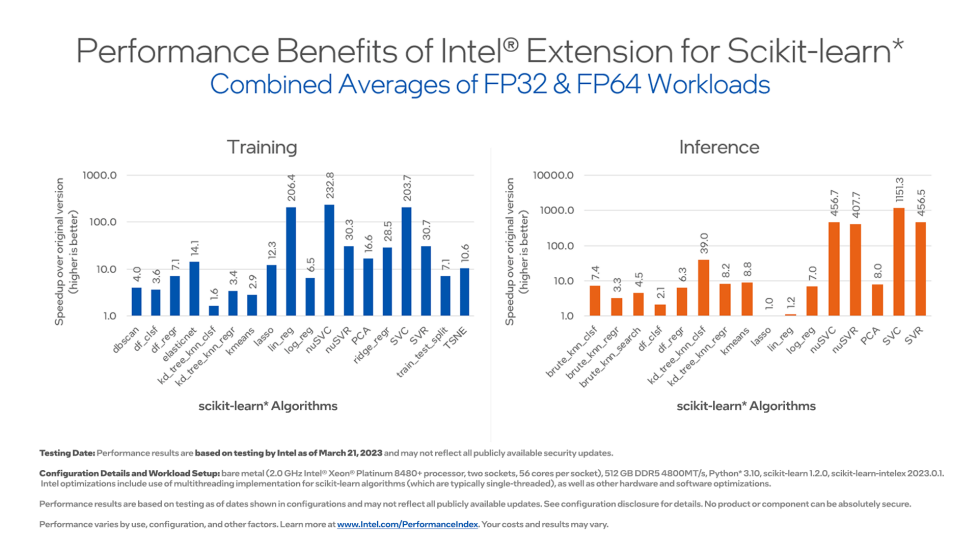
Extension for Scikit-learn* is a free software AI accelerator designed to deliver up to 100X faster performance for your existing scikit-learn code. The software acceleration is achieved with vector instructions, AI hardware-specific memory optimizations, threading, and optimizations.
Benefits:
Speed up training and inference by up to 100x with equivalent mathematical accuracy.
Benefit from performance improvements across different hardware configurations, including GPUs and multi-GPU configurations.
Integrate the extension into your existing scikit-learn applications without code modifications.
Continue to use the open-source scikit-learn API.
Enable and disable the extension with a couple of lines of code or at the command line.
See About the Extension for Scikit-learn* for more information.
Quick Install
pip install scikit-learn-intelex
conda install -c conda-forge scikit-learn-intelex --override-channels
See the full Installation Instructions for more details.
Example Usage
import numpy as np
from sklearnex import patch_sklearn
patch_sklearn()
from sklearn.cluster import DBSCAN
X = np.array([[1., 2.], [2., 2.], [2., 3.],
[8., 7.], [8., 8.], [25., 80.]], dtype=np.float32)
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
See Patching Utilities for more details.
import numpy as np
from sklearnex.cluster import DBSCAN
X = np.array([[1., 2.], [2., 2.], [2., 3.],
[8., 7.], [8., 8.], [25., 80.]], dtype=np.float32)
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
Running on GPUs
Note: executing on GPU requires installing package scikit-learn-intelex-gpu, and comes with additional system software requirements - see GPU support for details.
import numpy as np
from sklearnex import patch_sklearn, config_context
patch_sklearn()
from sklearn.cluster import DBSCAN
X = np.array([[1., 2.], [2., 2.], [2., 3.],
[8., 7.], [8., 8.], [25., 80.]], dtype=np.float32)
with config_context(target_offload="gpu:0"):
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
import os
os.environ["SCIPY_ARRAY_API"] = "1"
import numpy as np
import torch
from sklearnex import patch_sklearn
patch_sklearn()
from sklearn import config_context
from sklearn.cluster import DBSCAN
X = np.array([[1., 2.], [2., 2.], [2., 3.],
[8., 7.], [8., 8.], [25., 80.]], dtype=np.float32)
X = torch.tensor(X, device="xpu")
with config_context(array_api_dispatch=True):
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
import numpy as np
from sklearnex import config_context
from sklearnex.cluster import DBSCAN
X = np.array([[1., 2.], [2., 2.], [2., 3.],
[8., 7.], [8., 8.], [25., 80.]], dtype=np.float32)
with config_context(target_offload="gpu:0"):
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
import os
os.environ["SCIPY_ARRAY_API"] = "1"
import numpy as np
import torch
from sklearnex import config_context
from sklearnex.cluster import DBSCAN
X = np.array([[1., 2.], [2., 2.], [2., 3.],
[8., 7.], [8., 8.], [25., 80.]], dtype=np.float32)
X = torch.tensor(X, device="xpu")
with config_context(array_api_dispatch=True):
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
See GPU support for other ways of executing on GPU.