Decision Tree#
Decision trees partition the feature space into a set of hypercubes, and then fit a simple model in each hypercube. The simple model can be a prediction model, which ignores all predictors and predicts the majority (most frequent) class (or the mean of a dependent variable for regression), also known as 0-R or constant classifier.
Decision tree induction forms a tree-like graph structure as shown in the figure below, where:
Each internal (non-leaf) node denotes a test on features
Each branch descending from node corresponds to an outcome of the test
Each external node (leaf) denotes the mentioned simple model
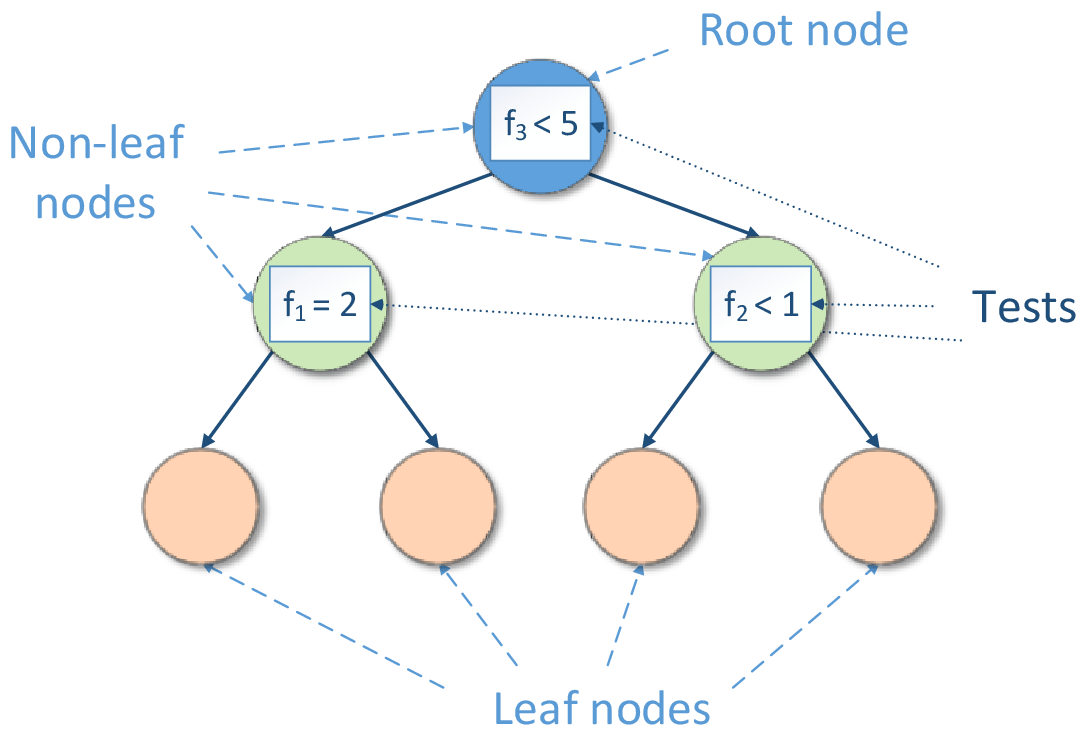
Decision Tree Structure#
The test is a rule for partitioning of the feature space. The test depends on feature values. Each outcome of the test represents an appropriate hypercube associated with both the test and one of descending branches. If the test is a Boolean expression (for example, \(f < c\) or \(f = c\), where \(f\) is a feature and \(c\) is a constant fitted during decision tree induction), the inducted decision tree is a binary tree, so its each non-leaf node has exactly two branches (‘true’ and ‘false’) according to the result of the Boolean expression.
Prediction is performed by starting at the root node of the tree, testing features by the test specified by this node, then moving down the tree branch corresponding to the outcome of the test for the given example. This process is then repeated for the subtree rooted at the new node. The final result is the prediction of the simple model at the leaf node.
Decision trees are often used in popular ensembles (e.g. boosting, bagging or decision forest).
Details#
Given n feature vectors \(x_1 = (x_{11}, \ldots, x_{1p}), \ldots, x_n = (x_{n1}, \ldots, x_{np})\) of size \(p\) and the vector of responses \(y = y_1, \ldots, y_n\), the problem is to build a decision tree.
Split Criteria#
The library provides the decision tree classification algorithm based on split criteria Gini index [Breiman84] and Information gain [Quinlan86], [Mitchell97]. See details in Classification Decision Tree.
The library also provides the decision tree regression algorithm based on the mean-squared error (MSE) [Breiman84]. See details in Regression Decision Tree.
Types of Tests#
The library inducts decision trees with the following types of tests:
For continuous features, the test has a form of \(f_j < constant\), where \(f_j\) is a feature, \(j \in \{1, \ldots, p\}\).
While enumerating all possible tests for each continuous feature, the constant can be any threshold as midway between sequential values for sorted unique values of given feature \(f_j\) that reach the node.
For categorical features, the test has a form of \(f_j = constant\), where \(f_j\) is a feature, \(j \in \{1, \ldots, p\}\).
While enumerating all possible tests for each categorical feature, the constant can be any value of given feature \(f_j\) that reach the node.
For ordinal features, the test has a form of \(f_j <> constant\) where \(f_j\) is a feature, \(j \in \{1, \ldots, p\}\).
While enumerating all possible tests for each ordinal feature, the constant can be any unique value except for the first one (in the ascending order) of given feature \(f_j\) that reach the node